29 Nov 2021
Towards Efficient and Generalizable Dexterous Manipulation with Reinforcement Learning using AWS

Zheng Xiong - AIMS CDT Student
Despite that robots driven by hard-coded instructions have achieved great success in the past decades, their applications are still quite limited in highly controlled scenarios due to the lack of adaptability to flexible environments with unforeseen variations. Moreover, robotic programming requires extensive human expertise and trial-and-errors, and the programming complexity of some dexterous manipulation tasks is even beyond the scope of human experts.
Reinforcement learning (RL) has the potential to tackle these challenges by automatically learning the optimal control policy. However, existing RL algorithms are mainly limited in the following aspects:
1. Sample inefficiency. It usually requires millions of steps to train an RL policy, which is very time consuming even in simulation, let alone on real-world robots.
2. Sparse reward. The intrinsic rewards of robotic manipulation are usually sparse, such as a binary signal of whether a destination is reached or not, which makes learning much harder. Although reward shaping can provide more feedback with hand-crafted dense rewards, it is very laborious and may introduce human bias which leads to sub-optimal or even unexpected learning outcomes.
3. Poor generalization. Existing RL algorithms are usually trained specifically for a certain task or a small set of tasks, thus are very prone to task variations in dynamic environments.
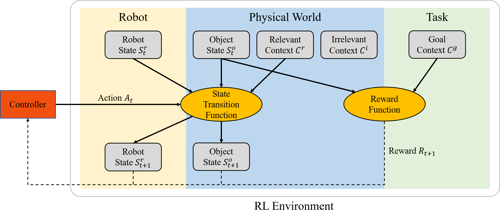
This project aims to tackle these challenges for a specific type of dexterous manipulation task of moving a block to arbitrary destinations with a tri-finger robot, which presents an useful yet challenging skill to learn. This figure illustrates the Markov Decision Process (MDP) framework for solving the tasks considered in this project. We decompose the environment for the RL controller into three parts as robot, physical world, and task. The robot consists of the robot state which can be directly manipulated by the controller. The physical world consists of object state (such as block pose) which can be indirectly manipulated by the controller through interaction, task-relevant context (such as block mass) which can influence the state transition dynamics, and task-irrelevant context (such as block color) which has no effect on transition dynamics. The task consists of goal context (such as goal pose) which, together with the object state, determines the sparse reward in each step. Based on this framework, we highlight four desired properties of a good RL algorithm for dexterous manipulation:
1. Generalization to different goals. We want to learn a versatile multi-goal RL policy which can adaptively achieve different goals in the same task family, such as pushing a box to different positions in a room.
2. Learning with little reward engineering. Little human intervention should be involved in reward shaping to reduce human bias and workload.
3. Adaptation to task-relevant context. The controller should be robust to variation of task-relevant context. For example, a picking policy should be adaptive enough to lift blocks with different mass.
4. Invariance to task-irrelevant context. The control's behavior should not be influenced by task-irrelevant context for robust control. For example, the color of walls in a room should not influence a robot's behavior to manipulate objects.
In this project, we aim to learn RL policies which satisfy the above four criteria for dexterous manipulation. The first two goals are closely related to the reward function, while the last two goals are involved in the state transition function. Thus we design a two-stage strategy to accomplish these goals, while different techniques are utilized to tackle the key challenge in each stage.
In the first stage, we try to achieve the first two goals by learning a goal-conditioned policy with sparse reward. The context variables are fixed to some default values, so we do not need to consider context adaptation in this stage yet. However, even without context variations, learning goal-conditioned policies with sparse reward is still challenging. To tackle this challenge, we utilize curriculum learning to improve learning efficiency, which automatically proposes new tasks with increasing difficulties to guide the controller's learning. Specifically, as all the manipulation tasks considered in this project should be solved by moving an object to a goal position, we use a path planner to generate pseudo goals with adequate difficulty as the learning curriculum.
In the second stage, we continue to fine-tune the policy learned from the first stage in different environments with context variations to improve its generalization. In this stage, we first do an intervention-based simulation test to identify task-relevant and task-irrelevant context. Then we train the policy in a compact search space formed by the identified task-relevant context. Furthermore, instead of randomly sampling in the search space, we propose a particle filter-based curriculum to focus more on the harder context variations to achieve better generalization.
We conduct simulated experiments on three single-object manipulation tasks from the CausalWorld benchmark. Experimental results show that in the first stage, our path planner-based curriculum improves the learning efficiency on simple tasks, and better solves the harder tasks where vanilla RL algorithms fail; In the second stage, our particle filter-based curriculum helps improve the policy's generalization to context variations. This video shows some example trials of solving a very hard pick and place task with the tri-finger robot.
The computational resources for the experiments in this project are kindly supported by Amazon Web Services (AWS) with £500 of cloud credits. Reinforcement learning experiments are known to be computationally expensive, and the results of this project can not be achieved without the computational resources supported by AWS.
I mainly used the EC2 service in AWS to run the reinforcement learning experiments. The web interface for instance management is user-friendly, which helps me conveniently manage multiple instances in a very clear way. The machine learning instance templates provided in EC2 are also quite helpful, which make it very easy for me to setup the experimental environments.



